Web Scraper是一款免费且适用于普通用户的爬虫工具,能够通过简单的鼠标操作和配置来获取各种数据,例如知乎回答列表、微博热门、微博评论、电商网站商品信息、博客文章列表等。
原理
我们使用Web Scraper一般是为了批量获取数据,因为手工方式太耗时费力,甚至根本无法完成。例如抓取微博热门前100条,或知乎某个问题的所有答案,这些任务都需要工具的帮助。
Web Scraper是一款界面简单、操作简单的工具,可以导出Excel格式的数据,不懂开发的用户也可以很快上手。
数据爬取思路
通过一个或多个入口地址,获取初始数据。例如一个文章列表页,或带有分页的列表页。
根据入口页面的某些信息,例如链接指向,进入下一级页面,获取必要信息。
根据上一级的链接继续进入下一层,获取必要信息(此步骤可以无限循环下去)。
接下来,我们正式认识一下Web Scraper这个工具。
实例
先通过以下页面下载插件的最新版本,并参考步骤安装到chrome中

初次打开 Web Scraper,你可以使用快捷键 F12(Windows)或 command+option+i(Mac)来打开开发者工具,或者鼠标右键点击检查。

打开Web Scraper后,你将看到开发者工具的完整界面和Web Scraper区域,红色框部分即为Web Scraper。
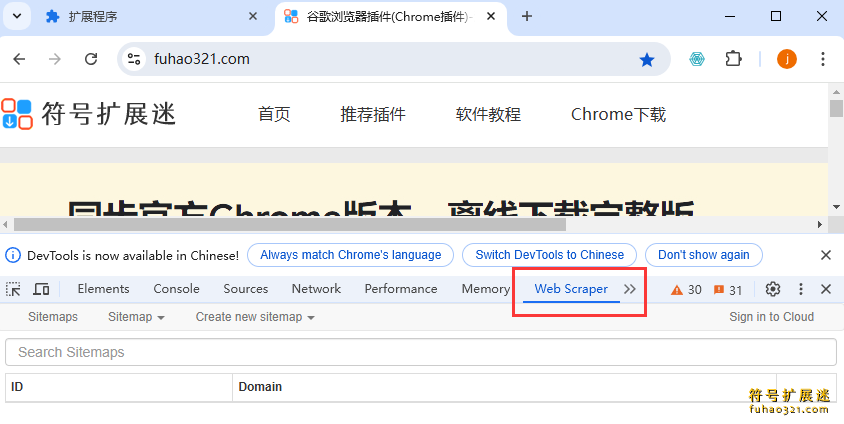
比如我们需要把https://www.fuhao321.com/这个网站的数据抓取下来,那么接下来,你可以按照以下步骤来使用Web Scraper:
1、创建新的抓取任务:在Web Scraper区域中,点击“Create new sitemap”按钮创建一个新的站点地图。
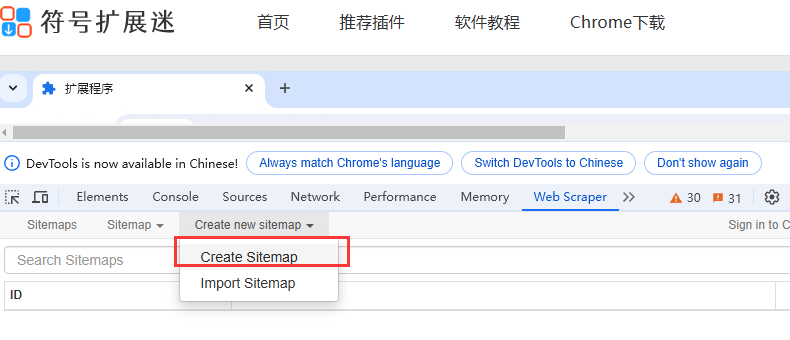
2、配置Sitemap:输入Sitemap的名字,及开始的URL,然后点击“Create sitemap”按钮。
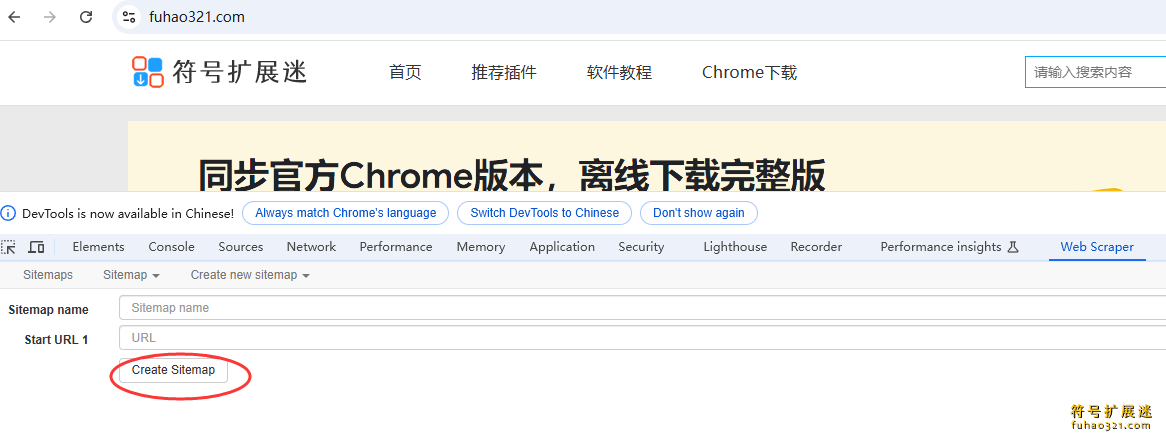
3、新增选择器:点击“Add new selector”按钮。
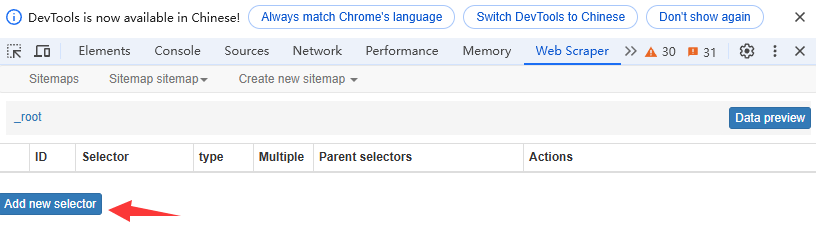
4、选择抓取类型:选择适合你的抓取类型,例如网页、Sitemap、或通过点击器进行抓
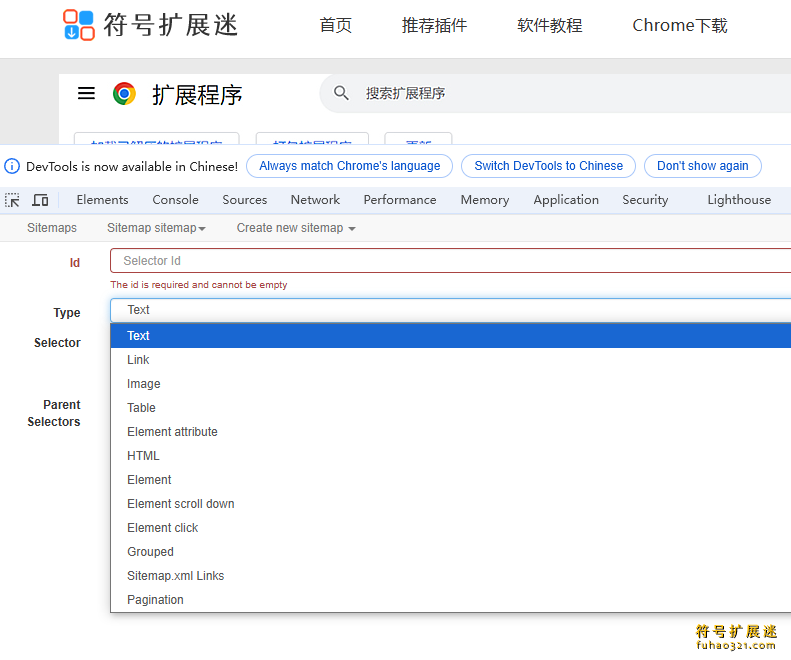
5、配置选择器:在选择器选项卡中,添加选择器并配置它们,以便Web Scraper可以准确地识别要抓取的数据。
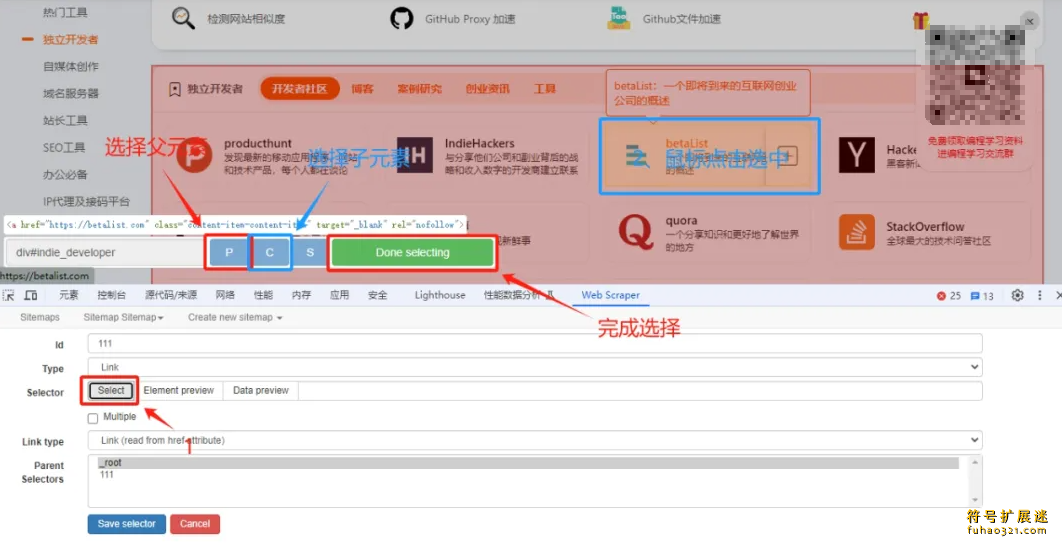
6、选择区域:然后配置选择器,查看HTML元素,是否是你想要抓取的数据。
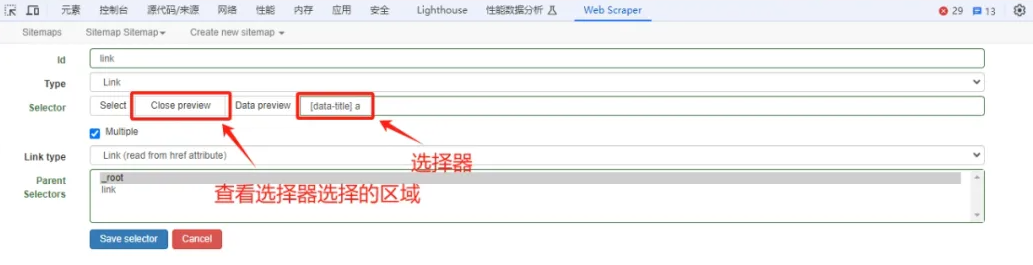
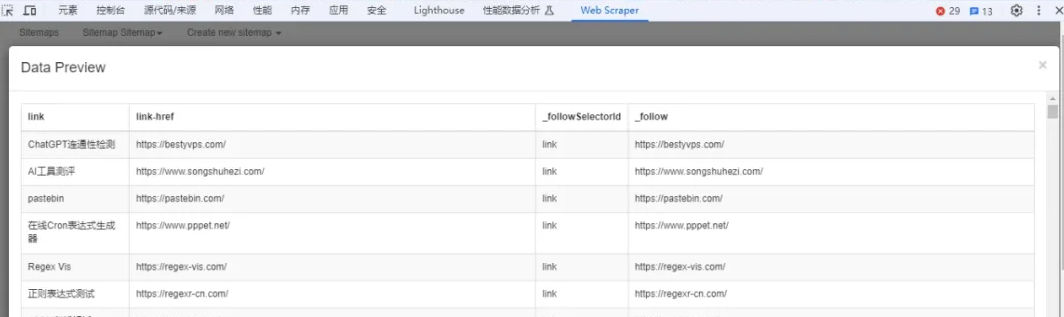
7、查看数据:然后点击"Data preview"按钮,查看抓取数据,没问题后再保存。
8、运行抓取任务:配置完成后,点击“Sitemap Sitemap --> Scrape”按钮来运行抓取任务,Web Scraper会开始抓取数据。

9、导出抓取配置:如果需要,点击“Sitemap Sitemap --> Scrape”按钮导出数据,可以支持.xlsx、.csv,以便在其他地方使用相同的配置。
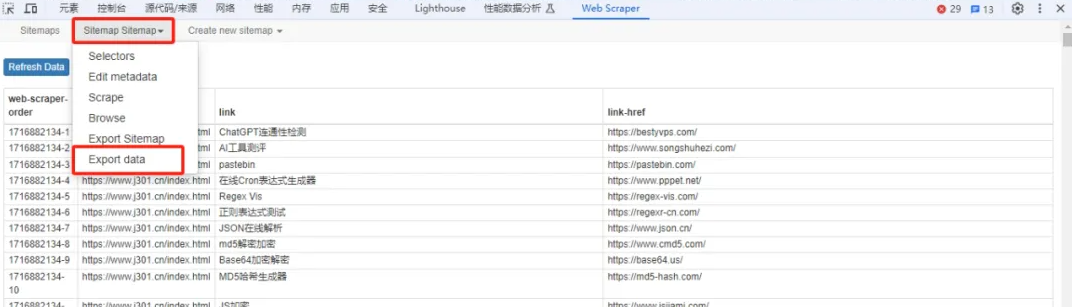
10、查看抓取结果:最后,你可以查看抓取到的数据,并对其进行进一步处理或分析。
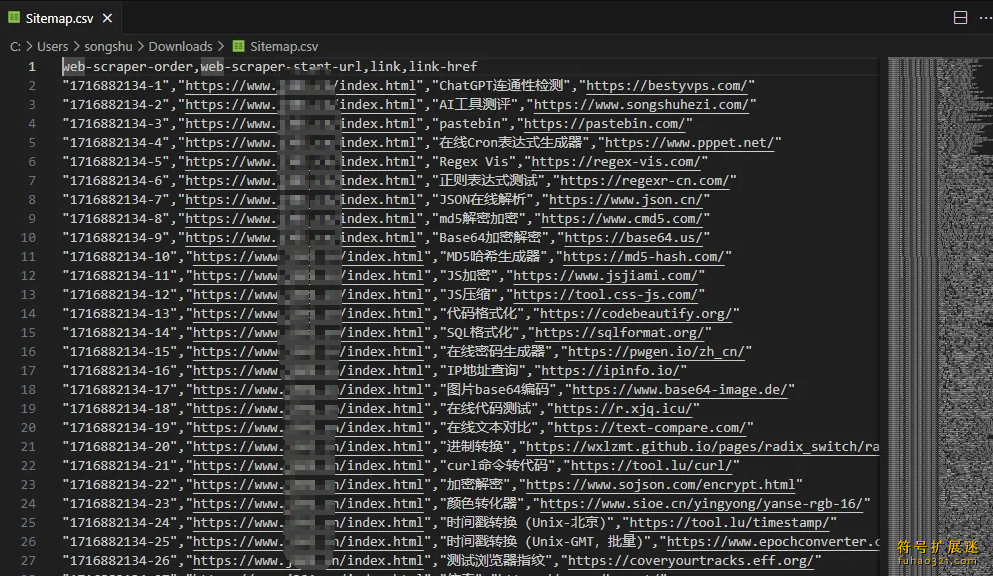
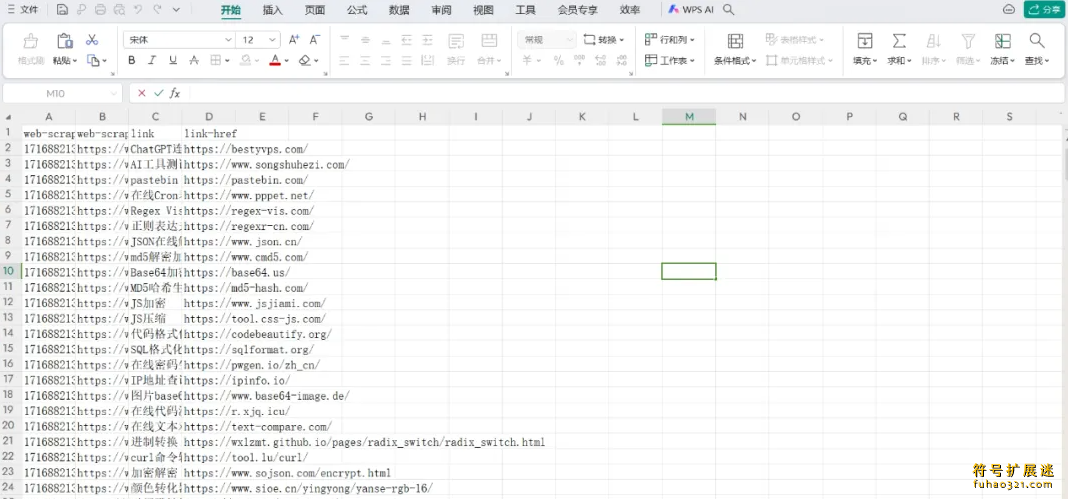
这样,就轻松把数据抓取下来了,可以在本地进行后续操作。

 Location Guard
Location Guard
 Request X
Request X
 Redux DevTools
Redux DevTools
 Outomated Test Recorder
Outomated Test Recorder PicHostify
PicHostify Lightning Copy
Lightning Copy Lightning Studio
Lightning Studio
用户评论