

插件介绍
OCR - Image Reader是一款在浏览器中提取图片中文字的Chrome插件,直接在浏览器中选中需要进行文字识别的地方,插件就会自动工作,转换文字,凭借其支持超过100种语言的tesseract.js库完成识别工作,识别过程包括自动检测文本方向及脚本,并在检测过程中显示一个进度条,还支持数据训练,一起来看下这款插件的具体内容吧。
插件功能特点
支持从图片、PDF、Powerpoint中提取文字信息,甚至在部分网页禁止的区域也能提取到内容
支持超过100种语言的OCR识别,确保高效的文本翻译与转化
提供自动检测文本方向及脚本的功能,增加识别的准确性
允许用户通过拖放修改后的图片重新进行识别,适合多种使用场景
具备图像语言检测功能(测试版),进一步提升语言识别的广度
在低置信度时自动反转图像以提高识别精准度,适用于深色模式
用户使用经验
1. 第一次运行时,扩展程序可能需要几分钟的时间才能从互联网获取训练数据。由于该资源已被缓存,因此所有后续调用都会很快。
2. 光学字符识别(OCR)速度较慢,因此此扩展为每个检测模块显示一个进度条。
3. 此扩展可以离线进行 OCR 处理。没有服务器端交互。它只获取语言训练数据库一次。
4. 该工具可用于从图像、PDF文档、Powerpoint幻灯片中提取文本内容,或者在禁止用户部分时提取网页内容。
5. 如果文本提取置信度较低,扩展程序会反转图像并重试(在深色主题上特别有用)
6.如果文字提取不准确,您可以修改图片并将其拖放到界面中重试。
插件安装使用
1、下载OCR - Image Reader插件的CRX文件

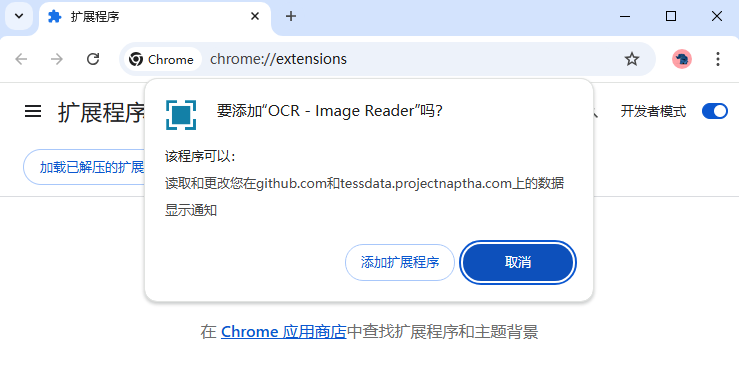
2、打开Chrome选择右上角的菜单图标,然后选择[扩展程序]-[管理扩展程序]或直接在地址栏输入[chrome://extensions/],开启[开发者模式],将刚下载的CRX文件拖放到扩展管理页面中,点击提示框中的[添加扩展程序]按钮完成安装,此时插件的图标会出现在浏览器右上角
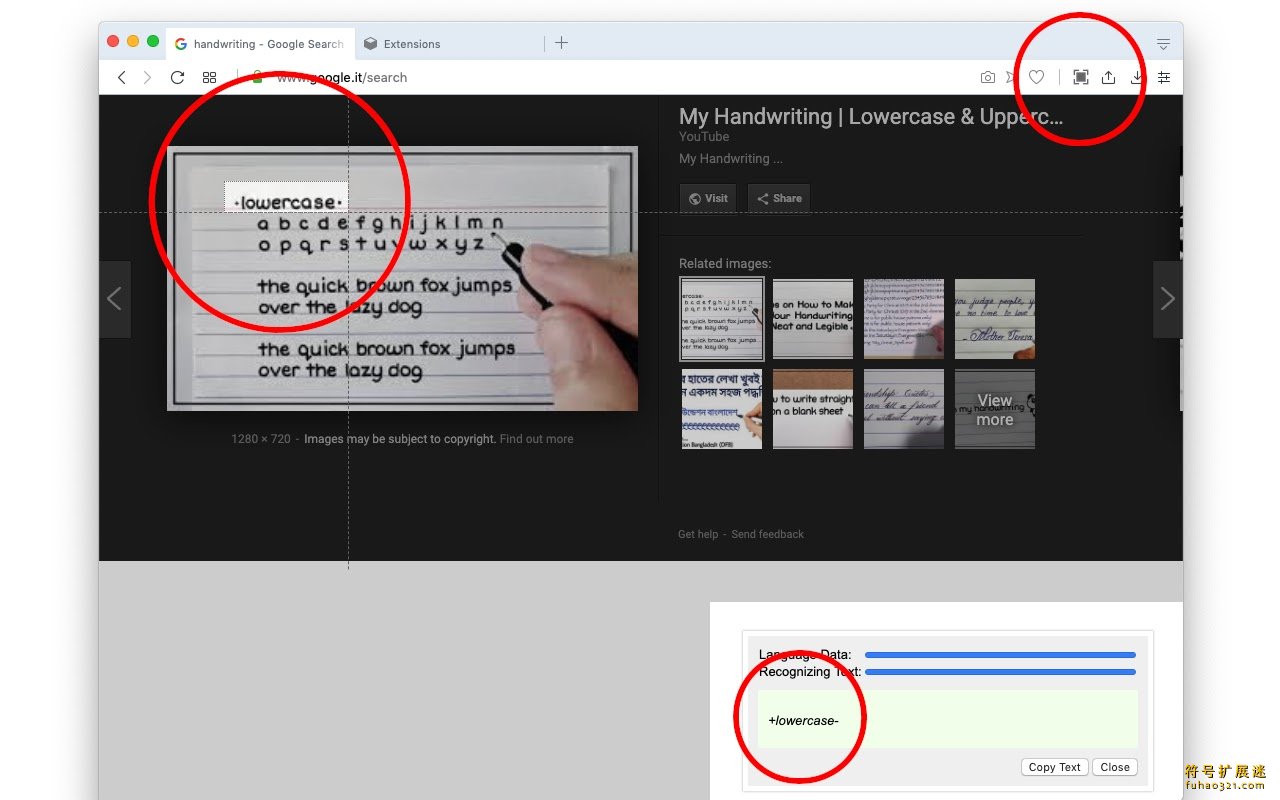
3、安装后,点击浏览器右上方的插件图标,根据提示选择需要识别的区域
4、等待OCR过程完成,查看插件界面上显示的识别结果
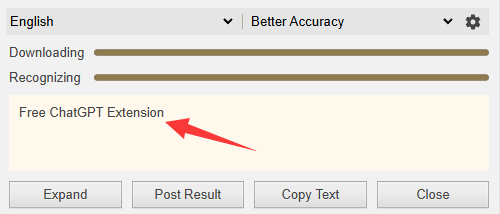
5、如果首次使用缓慢,请等待训练数据缓存完成,后续使用将更加流畅
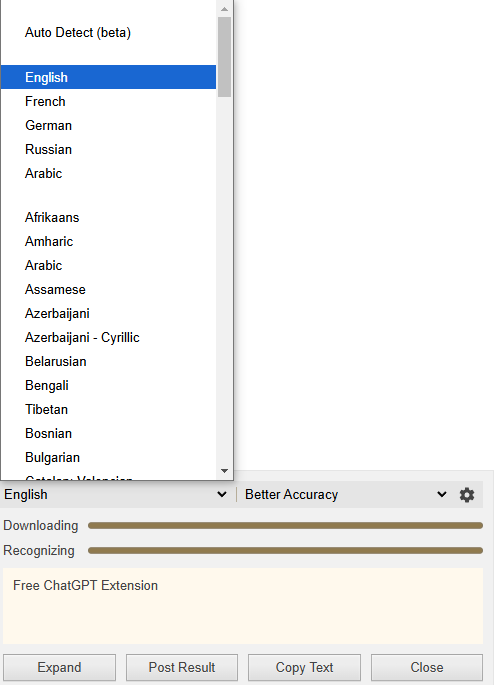
注意,大家在识别的时候,需要选择识别的语言和之别质量,不然没法精准识别
 Imageye下载
Imageye下载 TinEye Reverse Image Search下载
TinEye Reverse Image Search下载 Location Guard
Location Guard
 Request X
Request X Redux DevTools
Redux DevTools
 Outomated Test Recorder
Outomated Test Recorder PicHostify
PicHostify Lightning Copy
Lightning Copy Lightning Studio
Lightning Studio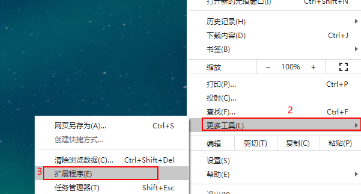
用户评论