

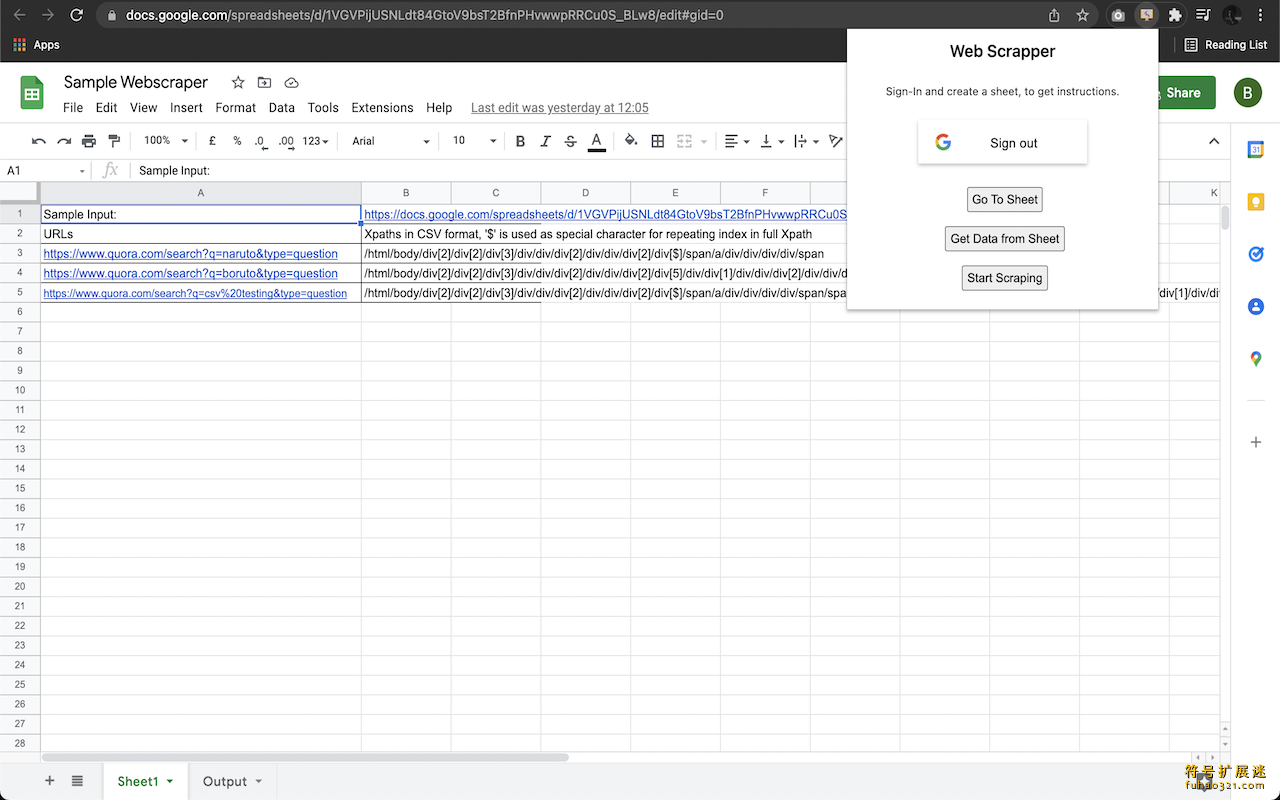
插件介绍
Web Scraper是一款能够从网页中提取数据的工具,可以批量抓取网站中的结构化内容。通过设置目标网址和自定义规则,这款工具能够帮助用户实现自动化数据采集,尤其适合处理多网站信息提取需求。接下来的内容将详细介绍插件的功能特点和安装步骤。

注意事项
- 插件只适用于合法的场景,用户需要确保抓取内容的行为符合相关规定。
- 某些网页隐藏的图片或动态内容可能无法直接抓取,可以结合开发者工具使用。
- 对于复杂动态加载的网站,插件可能无法完全处理,可以根据需要选择其他方法。
插件功能特点
1、列出目标网站的 URL,并设置对应的 Xpath 规则后,插件会自动从网页中提取需要的数据,整个过程直接通过浏览器完成,无需任何额外工具。
2、用户只需加载目标网址和规则,点击“开始抓取”按钮,插件就会自动运行,采集到指定数据,使用过程直观高效。
3、无论是表格信息、文本内容还是图片链接,只要网站结构清晰,就能提取对应内容,尤其适合需要处理批量数据的用户。
插件安装及使用
第一步:从页面底部的下载链接中下载 Web Scraper 插件的 CRX 文件,并确认文件 ID 是 dogiinkejekngjnphjklkdohanocpnfj。

第二步:打开 Chrome 浏览器,点击右上角“三点”图标,进入 [扩展程序]-[管理扩展程序],或者直接在地址栏输入 chrome://extensions/ 进入扩展管理页面。

第三步:找到右上角的“开发者模式”开关,将其开启(显示蓝色)。
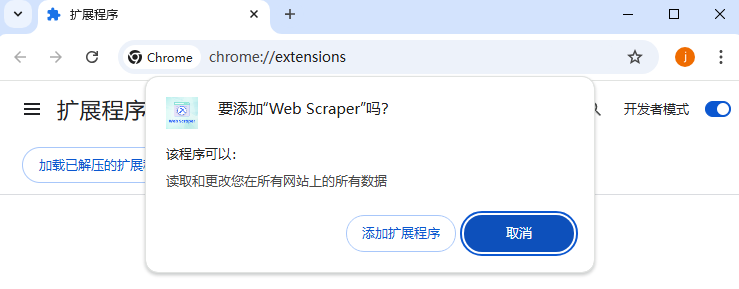
第四步:将下载的 CRX 文件拖放到扩展程序页面,根据提示点击“添加扩展程序”完成安装。
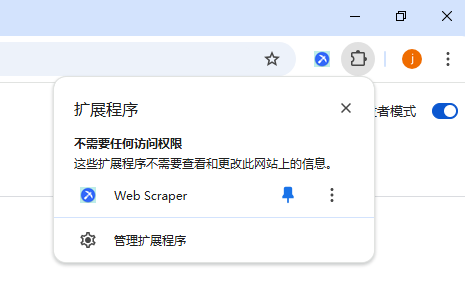
第五步:完成安装后,回到浏览器界面,在右上角区域找到插件的启动图标,表示插件已经成功安装。
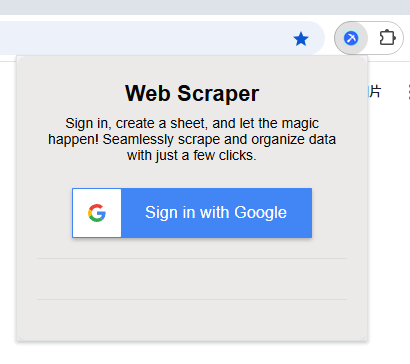
第六步:使用之前需要先登录,我们这里用谷歌默认账户
 PrintFriendly下载
PrintFriendly下载 Cisco Webex Extension下载
Cisco Webex Extension下载 炭黑+银色金属下载
炭黑+银色金属下载 Selective Bookmarks Export Tool下载
Selective Bookmarks Export Tool下载 Web Scraper下载
Web Scraper下载 声音增强器下载
声音增强器下载 1Password下载
1Password下载 Location Guard
Location Guard
 Request X
Request X
 Redux DevTools
Redux DevTools Outomated Test Recorder
Outomated Test Recorder PicHostify
PicHostify Lightning Copy
Lightning Copy Lightning Studio
Lightning Studio
用户评论